Pythonでスクレイピングした情報をLINE Notifyで通知する
Tag:
pythonはじめに
前回のLINE Notifyの利用が思いのほか簡単だったので、今回はスクレイピングしたものをLINE Notifyで通知するテスト。
スクレイピング素材
スクレイピングするサイトは一日あたり5,6件のニュースを配信しているのですが、RSSフィードを配信していないので
一日一回LINEで受け取れるようにしたいと思います。
スクレイピング
定番のBeautifulSoupでスクレイピング。
まずはchromeの右クリでページのソースを表示かF12のデベロッパーツールで抽出したい場所を調べる。
<div id="news-area" class="body-area">内の
<a href=~~が記事のリンク<p class="inline-item text-title photo">が記事のタイトル<p class="time inline-item">が投稿日時と時間
リンクとタイトルを取得してLINE Notifyに送ると3,4日分取得してしまうので、当日分だけ送るようにする。
使用するパッケージ等は
- requests
- re
- BeautifulSoup
- datetime
def main():
today = datetime.datetime.today().strftime("%m/%d") #今日の日付を取得
headers = {'User-Agent': 'Mozilla/5.0'}
res = requests.get('https://world.jra-van.jp/news/', headers=headers)
soup = BeautifulSoup(res.content, "html.parser")
for news in soup.find_all("div", id="news-area"):
for a in news.find_all("a"):
link = a.get("href")
if a.find_all(text=re.compile(today)): #今日の日付とマッチした記事だけ取得
for title in a.find_all("p", class_="inline-item text-title photo"):
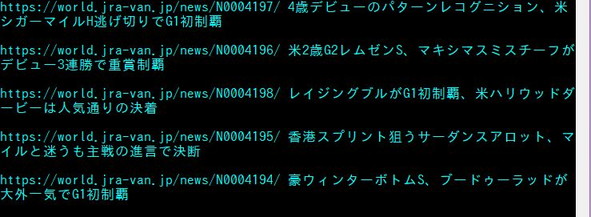
print('https://world.jra-van.jp'+link, title.get_text() + "\n")
if __name__ == '__main__':
main()
スクレイピング成功
LINE Notifyで通知
import requests
import re
from bs4 import BeautifulSoup
import datetime
def line(mes):
url = "https://notify-api.line.me/api/notify"
token = "取得したトークン"
headers = {"Authorization": "Bearer " + token}
message = '\n' + mes
payload = {"message": message}
requests.post(url, headers=headers, params=payload)
def main():
today = datetime.datetime.today().strftime("%m/%d")
headers = {'User-Agent': 'Mozilla/5.0'}
res = requests.get('https://world.jra-van.jp/news/', headers=headers)
soup = BeautifulSoup(res.content, "html.parser")
for news in soup.find_all("div", id="news-area"):
for a in news.find_all("a"):
link = a.get("href")
if a.find_all(text=re.compile(today)):
for title in a.find_all("p", class_="inline-item text-title photo"):
texts = 'https://world.jra-van.jp'+link, title.get_text()
#変数textsはタプルなのでこのままだとエラーになる
text = "\n".join(texts) #結合して文字列に変換
line(text)
if __name__ == '__main__':
main()
実行すると……
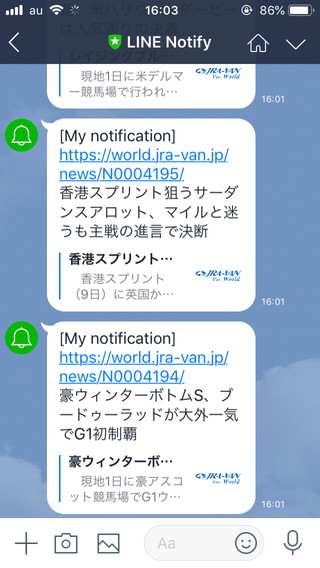
無事LINE Notifyで通知されました。
あとは一日一回cronで実行されるようにすれば完成。